Производительность¶
Вкладка Performance предоставляет информацию о скорости оценки, потреблении токенов и затратах.
Переключитесь на вкладку Performance, нажав на неё рядом с вкладкой Metrics.
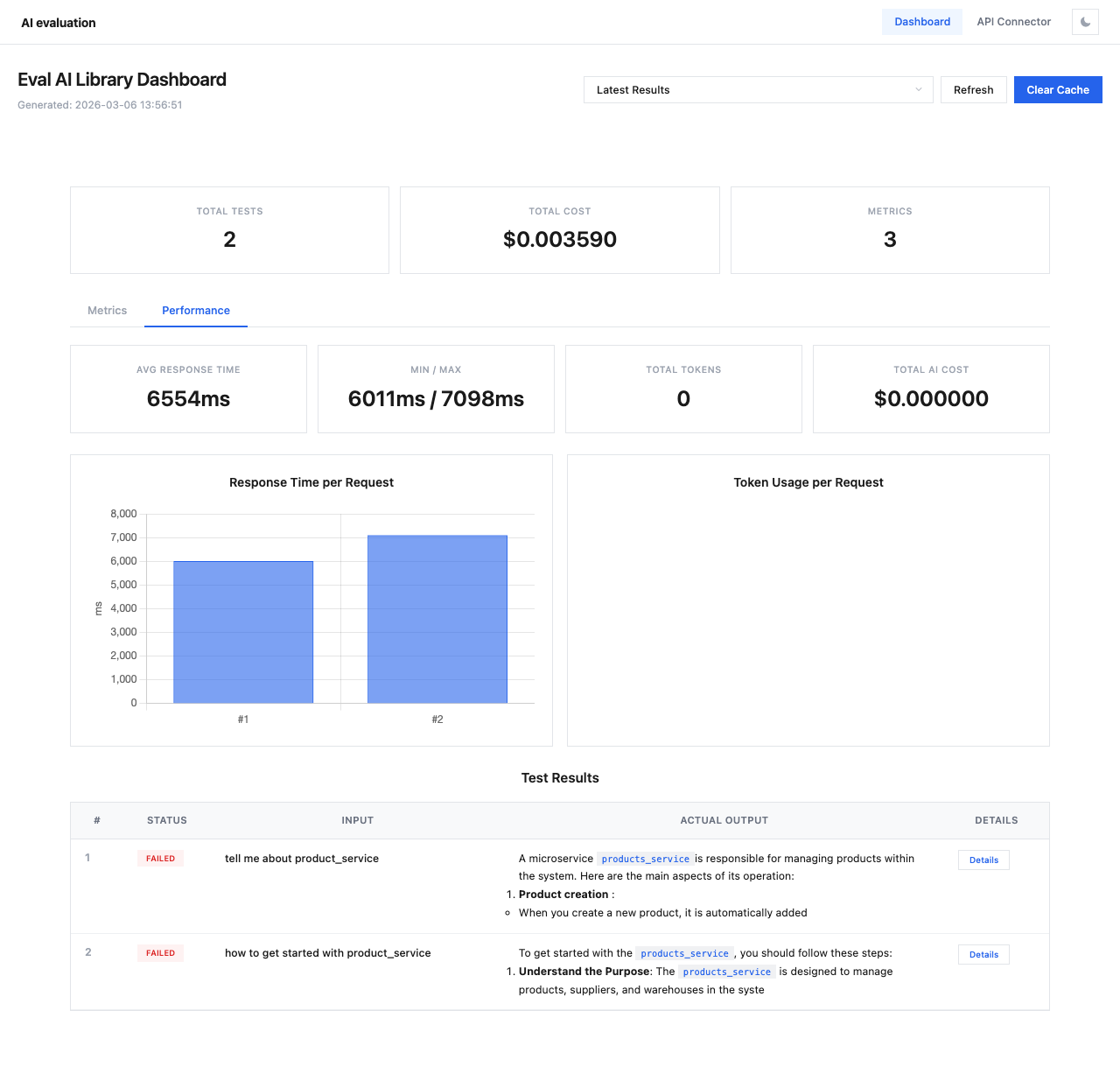
Карточки производительности¶
Четыре карточки отображают ключевые метрики производительности:
| Карточка | Описание |
|---|---|
| Avg Response Time | Среднее время ответа API по всем тест-кейсам |
| Min / Max | Самое быстрое и самое медленное время ответа |
| Total Tokens | Общее количество токенов по всем вызовам API |
| Total AI Cost | Суммарная стоимость всех вызовов API (отдельно от стоимости оценки) |
График времени ответа¶
Столбчатая диаграмма Response Time per Request показывает время ответа для каждого тест-кейса. Это помогает выявить:
- Выбросы с аномально медленными ответами
- Устойчивые паттерны производительности
- Возможные проблемы с rate limiting или throttling
График использования токенов¶
Диаграмма Token Usage per Request отображает потребление токенов по каждому тест-кейсу, что полезно для:
- Выявления многословных ответов, требующих оптимизации промптов
- Отслеживания бюджета токенов в рамках оценок
- Сравнения эффективности использования токенов разными моделями
Tip
Если время ответа стабильно высокое, попробуйте:
- Использовать более быструю модель для оценки (например,
gpt-4o-miniвместоgpt-4o) - Добавить
delay_between_requests_msдля избежания rate limiting - Уменьшить размер контекста в тест-кейсах